
Since adapters were first introduced to NLP as a light-weight alternative to full fine-tuning of language models (Houlsby et al., 2019), the relevance of efficient transfer learning methods has continuously gained importance throughout the field. With Transformer-based language models growing from millions to billions or trillions of parameters, the inherent advantages of methods such as adapters - parameter efficiency, computational efficiency and modularity - have only become even more relevant. Nowadays, the tool set of efficient fine-tuning methods contains a diverse palette of different methods, ranging from improved adapter architectures (Mahabadi et al., 2021, Ribeiro et al., 2021) to various methods of optimizing language model prompts (Li and Liang, 2021, Lester et al., 2021). Recent work also has made attempts at combining multiple methods into a single unified architecture (He et al., 2021, Mao et al., 2021)
With the release of version 3.0 of adapter-transformers today, we're taking the first steps at embracing this grown and diversified landscape of efficient fine-tuning methods.
Our library, an extension of the great Transformers library by HuggingFace, was introduced as a straightforward way to train, share, load and use adapters within Transformer models.
The new version for the first time allows using methods beyond the "classic" adapter architecture within this framework, namely Prefix Tuning, Parallel adapters, Mix-and-Match adapters and Compacters.
In the following sections, we will present all new features and methods introduced with the new release as well as all important changes one by one:
You can find adapter-transformers on GitHub or install it via pip:
pip install -U adapter-transformers
New Efficient Fine-Tuning Methods
Version 3.0 of adapter-transformers integrates a first batch of new efficient fine-tuning methods.
These include Prefix Tuning (Li and Liang, 2021), Parallel adapters, Mix-and-Match adapters (He et al., 2021) and Compacters (Mahabadi et al., 2021).
The newly added methods seamlessly integrate into the existing framework of working with adapters, i.e. they share the same methods for creation (add_adapter()), training (train_adapter()), saving (save_adapter()) and loading (load_adapter()).
Each method is specified and configured using a specific configuration class, all of which derive from the common AdapterConfigBase class.
Please refer to our documentation for more explanation on working with adapters.
Recap: Bottleneck Adapters
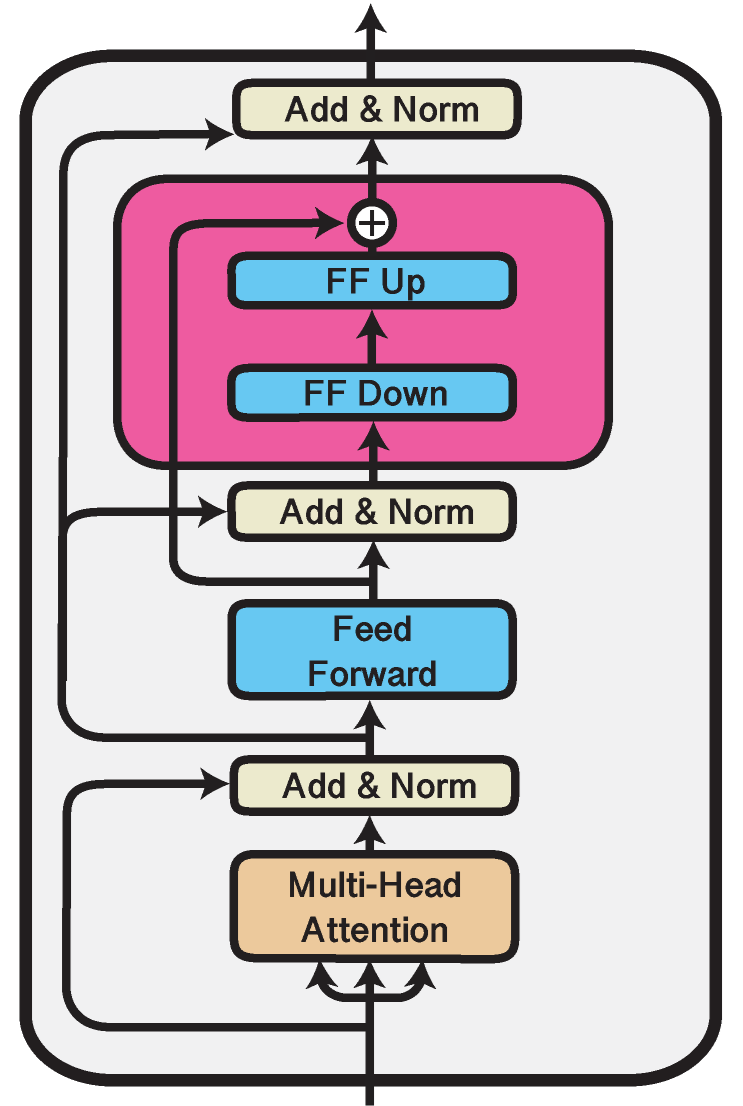
Until version 3.0 of adapter-transformers, we only supported bottleneck adapters. As illustrated above, small stitched-in layers that
consist of bottleneck feed-forward layers and a residual connection are added to the pre-trained transformer layers. These adapters are typically placed after the attention block and/or
after the feedforward layer. For further detail check out our documentation for
bottleneck adapters here.
Prefix Tuning
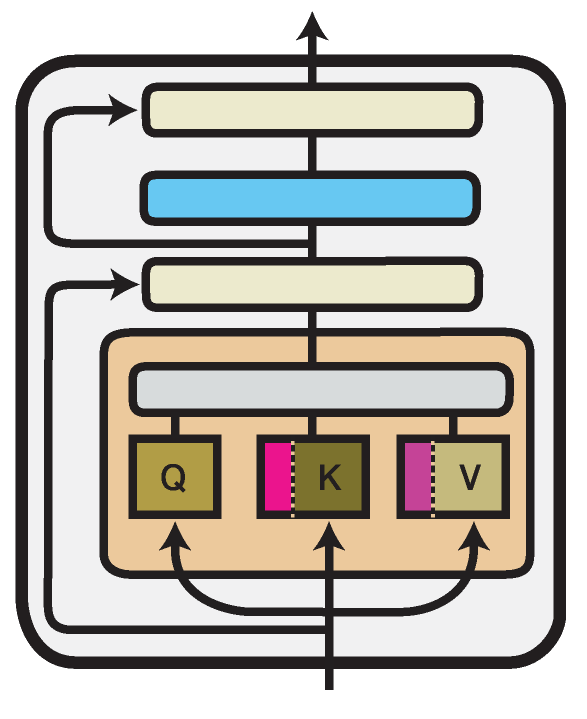
Prefix Tuning (Li and Liang, 2021) introduces new parameters in the multi-head attention blocks in each Transformer layer.
In the illustration above the prefixes are marked pink and purple. More, specifically, we prepend trainable prefix vectors and to the keys and values of the attention head input, each of a configurable prefix length (prefix_length attribute):
Following the original authors, the prefix vectors in and are not optimized directly, but reparameterized via a bottleneck MLP.
This behavior is controlled via the flat attribute of the configuration.
Using PrefixTuningConfig(flat=True) will create prefix tuning vectors that are optimized without reparameterization.
Example:
from transformers.adapters import PrefixTuningConfig
config = PrefixTuningConfig(flat=False, prefix_length=30)
model.add_adapter("prefix_tuning", config=config)
As reparameterization using the bottleneck MLP is not necessary for performing inference on an already trained Prefix Tuning module, adapter-transformers includes a function to "eject" a reparameterized Prefix Tuning into a flat one:
model.eject_prefix_tuning("prefix_tuning")
This will only retain the necessary parameters and reduces the size of the trained Prefix Tuning.
Results:
The following table compares initial runs of our Prefix Tuning implementation1 with the results reported by He et al. (2021).
| Task | Model | Metrics | Reference | Ours |
|---|---|---|---|---|
| SST-2 | roberta-base | Acc. | 94 | 94.72 |
| MNLI | roberta-base | Acc. | 86.3 | 86.1 |
| XSum | bart-large | R-1/R-2/R-L | 43.40/20.46/35.51 | 43.00/20.05/35.10 |
| WMT16 En-Ro | bart-large | BLEU | 35.6 | 35.0 |
Parallel & Mix-and-Match adapters
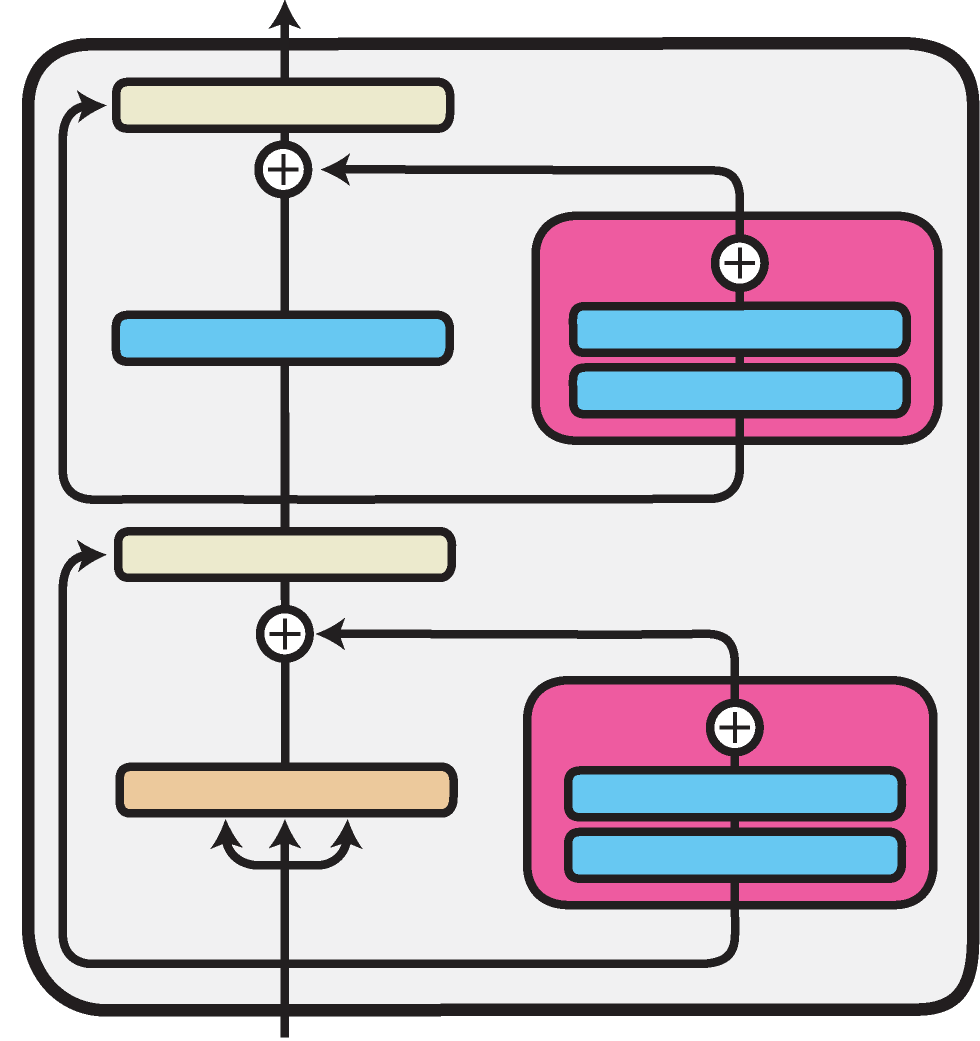
Parallel adapters have been proposed as a variant of the classic bottleneck adapter architecture. Here, activations are passed via the bottleneck adapter layer in parallel to the adapted Transformer sub-layer (i.e. feed-forward or attention layer), as opposed to the established, sequential, order of computations.
He et al. (2021) study various variants and combinations of efficient fine-tuning methods. Among others, they propose Mix-and-Match Adapters as a combination of Prefix Tuning and parallel adapters. This configuration is supported by adapter-transformers out-of-the-box:
from transformers.adapters import MAMConfig
config = MAMConfig()
model.add_adapter("mam_adapter", config=config)
and is identical to using the following ConfigUnion (see further below for more on ConfigUnion):
from transformers.adapters import ConfigUnion, ParallelConfig, PrefixTuningConfig
config = ConfigUnion(
PrefixTuningConfig(bottleneck_size=800),
ParallelConfig(),
)
model.add_adapter("mam_adapter", config=config)
Results:
The following table compares initial runs of our Mix-and-Match adapter implementation1 with the results reported by He et al. (2021).
| Task | Model | Metrics | Reference | Ours |
|---|---|---|---|---|
| SST-2 | roberta-base | Acc. | 94.2 | 94.26 |
| MNLI | roberta-base | Acc. | 87.4 | 86.47 |
| XSum | bart-large | R-1/R-2/R-L | 45.12/21.90/36.91 | 44.74/21.75/36.80 |
| WMT16 En-Ro | bart-large | BLEU | 37.5 | 36.9 |
Additionally, the next table shows initial runs of our parallel adapter implementation, again compared with the results reported by He et al. (2021) when applicable. We use a reduction factor of 2 (corresponding to a bottleneck dimension of 384 for roberta-base and 512 for bart-large).
| Task | Model | Metrics | Reference | Ours |
|---|---|---|---|---|
| SST-2 | roberta-base | Acc. | - | 94.61 |
| MNLI | roberta-base | Acc. | - | 86.41 |
| XSum | bart-large | R-1/R-2/R-L | 44.35/20.98/35.98 | 44.88/21.53/36.55 |
| WMT16 En-Ro | bart-large | BLEU | 37.1 | 36.4 |
Compacters
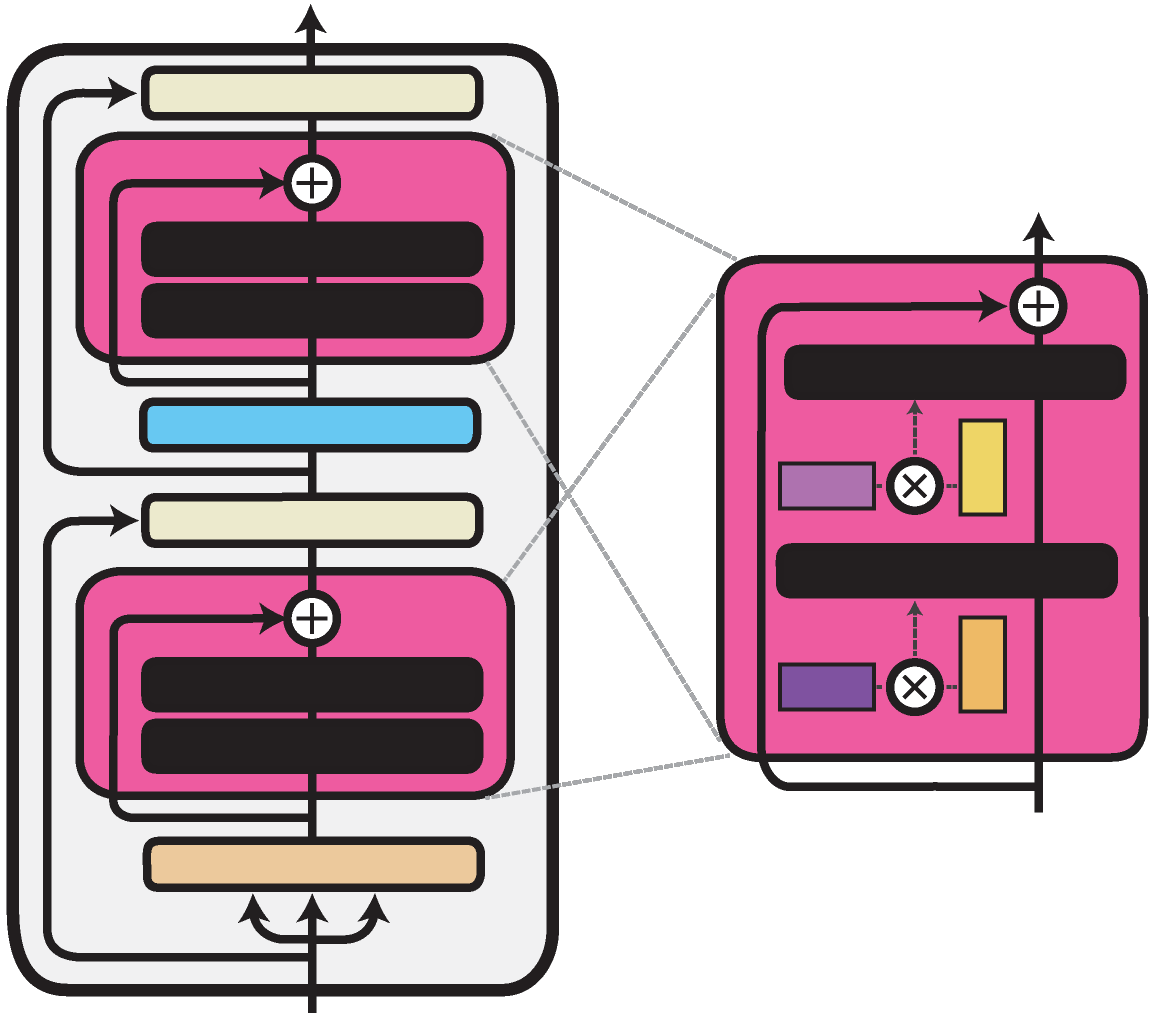
Another alternative to the classical bottleneck adapter is the Compacter (Mahabadi et al. (2021)). Here the linear down- and up-projection layer is replaced by a phm layer, which is marked in black on the illustration. In the phm layer, the weights matrix is constructed from two smaller matrices by computing their kroenecker product. These matrices can be factorized and shared between all transformer layers.
To add a Compacter in adapter-transformers, simply provide a CompacterConfigor a CompacterPlusPlusConfig when adding the adapter:
from transformers.adapters import CompacterPlusPlusConfig
config = CompacterPlusPlusConfig()
model.add_adapter("compacter_plusplus", config=config)
The following table compares the results of training a Compacter++1 for T5 for the glue tasks with the results reported in Mahabadi et al. (2021):
| Task | Metrics | Reference | Ours |
|---|---|---|---|
| COLA | Mathews Correlation | 61.27 | 58.45 |
| SST-2 | Acc. | 93.81 | 94.61 |
| MRPC | Acc./F1 | 90.69/93.33 | 87.99/91.81 |
| QQP | Acc./F1 | 90.17/86.93 | 90.33/87.46 |
| STS-B | Pearson/Spearman Correlation | 90.46/90.93 | 89.78/89.53 |
| MNLI | Acc. | 85.71 | 85.32 |
| QNLI | Acc. | 93.08 | 91.63 |
| RTE | Acc. | 74.82 | 77.25 |
Library Updates and Changes
Below, we highlight further updates and changes introduced with v3.0 of adapter-transformers.
You can find a full change log here.
XAdapterModel classes
Version 3.0 introduces a new set of model classes (one class per model type) specifically designed for working with adapters.
These classes follow the general schema XAdapterModel, where X is the respective model type (e.g. Bert, GPT2).
They replace the XModelWithHeads classes of earlier versions.
In summary, these classes provide the following main features:
- Flexible configuration of predictions heads (see documentation).
- Compositions (such as parallel inference and
BatchSplit) of adapters with different prediction heads. - One model class per model type, additionally, a
AutoAdapterModelclass for automatic class detection.
These classes are designed as the new default classes of adapter-transformers. It is recommended to use these classes for working with adapters whenever possible.
A usage example looks like this:
from transformers.adapters import AutoAdapterModel
# Load class
model = AutoAdapterModel.from_pretrained("bert-base-uncased")
# Configure adapters & heads
model.add_adapter("first_task")
model.add_adapter("second_task")
model.add_classification_head("first_task", num_labels=2)
model.add_multiple_choice_head("second_task", num_choices=4)
# Define active setup
model.train_adapter(Parallel("first_task", "second_task"))
# Start training loop ...
⚠️ All XModelWithHeads classes are now deprecated as the new classes are direct replacements.
Flexible configurations with ConfigUnion
While different efficient fine-tuning methods and configurations have often been proposed as standalone, it might be beneficial to combine them for joint training.
We have already seen this for the Mix-and-Match adapters proposed by He et al. (2021).
To make this process easier, adapter-transformers provides the possibility to group multiple configuration instances together using the ConfigUnion class.
For example, this could be used to define different reduction factors for the adapter modules placed after the multi-head attention and the feed-forward blocks:
from transformers.adapters import AdapterConfig, ConfigUnion
config = ConfigUnion(
AdapterConfig(mh_adapter=True, output_adapter=False, reduction_factor=16, non_linearity="relu"),
AdapterConfig(mh_adapter=False, output_adapter=True, reduction_factor=2, non_linearity="relu"),
)
model.add_adapter("union_adapter", config=config)
AdapterSetup context
As a replacement to the adapter_names parameter, v3.0 introduces a new AdapterSetup class for dynamic and state-less configuration of activated adapters.
This class is intended to be used as a context manager, i.e. a typical use case would look like this:
# will use no adapters
outputs = model(**inputs)
with AdapterSetup(Stack("a", "b")):
# will use the adapter stack "a" and "b"
outputs = model(**inputs)
Note that in the above example no adapters are activated via active_adapters. Within the with block, the adapter implementation will dynamically read the currently active setup from the context manager.
This solution allows dynamic adapter activation, e.g. also with nesting:
with AdapterSetup(Stack("a", "b")):
# will use the adapter stack "a" and "b"
outputs = model(**inputs)
with AdapterSetup(Fuse("c", "d"), head_setup="e"):
# will use fusion between "c" and "d" & head "e"
outputs = model(**inputs)
Most importantly, the context manager is thread-local, i.e. we can use different setups in different threads with the same model instance.
⚠️ Breaking change: The adapter_names parameter is removed for all model classes.
Refactorings
Besides the already mentioned changes, v3.0 of adapter-transformers comes with major refactorings in the integration of adapter implementations into model classes and model configurations (e.g., see here and here).
While these refactorings only affect the interface methods minimally, the process of integrating new model architectures has been substantially simplified.
Please refer to the updated model integration guide for more.
Transformers upgrade
Version 3.0 of adapter-transformers upgrades the underlying HuggingFace Transformers library from v4.12.5 to v4.17.0, bringing many awesome new features created by HuggingFace.
Conclusion
The release of version 3.0 of adapter-transformers today marks the starting point of integrating new efficient fine-tuning methods.
In this release, we integrated a first batch of recently proposed methods, including Prefix Tuning, Parallel adapters, Mix-and-Match adapters and Compacters.
Nonetheless, the range of available efficient fine-tuning methods goes far beyond these and continues to grow rapidly.
Thus, we expect to integrate more and more methods step by step.
Finally, as we're a very small team, your help on adapter-transformers is always very welcome.
Head over to our GitHub repository and reach out if you're interested in contributing in any way.
References
- Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., Laroussilhe, Q.D., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-Efficient Transfer Learning for NLP. ICML 2019.
- Mahabadi, R.K., Henderson, J., & Ruder, S. (2021). Compacter: Efficient Low-Rank Hypercomplex Adapter Layers. ArXiv, abs/2106.04647.
- Leonardo F. R. Ribeiro, Yue Zhang, and Iryna Gurevych. 2021. Structural Adapters in Pretrained Language Models for AMR-to-Text Generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4269–4282, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Xiang Lisa Li and Percy Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., & Neubig, G. (2021). Towards a Unified View of Parameter-Efficient Transfer Learning. ArXiv, abs/2110.04366.
- Mao, Y., Mathias, L., Hou, R., Almahairi, A., Ma, H., Han, J., Yih, W., & Khabsa, M. (2021). UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning. ArXiv, abs/2110.07577.