Nine months ago, we released Adapters, our new unified library for parameter-efficient and modular fine-tuning.
Adapters stands in direct tradition to our work on adapter-transformers since 2020, the first open-source library for parameter-efficient fine-tuning.
Since its initial release, Adapters has received various updates, the newest being released today.
In this post, we'll go through some of the most exciting new features released today and in the last few months.
You can find the full list of changes in the latest release in our release notes.
You can find Adapters on GitHub or install it via pip:
pip install -U adapters
Representation Fine-Tuning (ReFT)
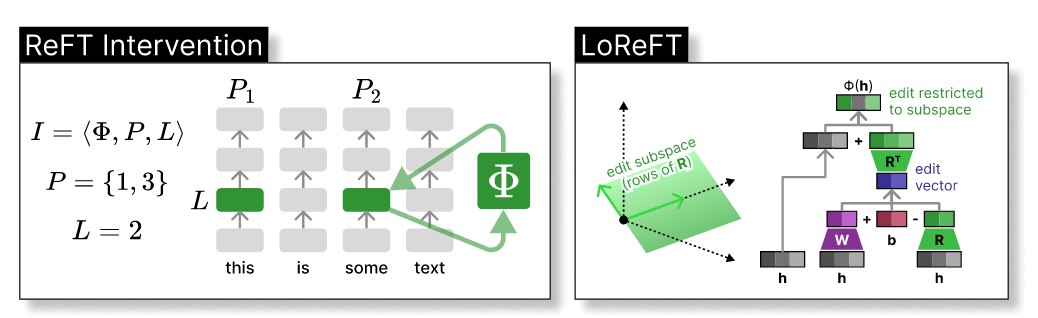
Representation Fine-Tuning (ReFT), proposed by Wu et al. (2024), is a novel efficient adapter method. It leverages so-called interventions to adapt the pre-trained representations of a language model. Within the context of ReFT, these interventions can intuitively be thought of as adapter modules placed after each Transformer layer. In the general form, an intervention function can thus be defined as follows:
Here, and are low-rank matrices of rank . is the layer output hidden state at a single sequence position, i.e. interventions can be applied independently at each position.
Based on this general form, the ReFT paper proposes multiple instantiations of ReFT methods supported by Adapters:
- LoReFT enforces orthogonality of rows in . Defined via
LoReftConfigor via theorthogonalityattribute as in the following example:
config = ReftConfig(
layers="all", prefix_positions=3, suffix_positions=0, r=1, orthogonality=True
) # equivalent to LoreftConfig()
- NoReFT does not enforce orthogonality in . Defined via
NoReftConfigor equivalently:
config = ReftConfig(
layers="all", prefix_positions=3, suffix_positions=0, r=1, orthogonality=False
) # equivalent to NoReftConfig()
- DiReFT does not enforce orthogonality in and additionally removes subtraction of in the intervention, Defined via
DiReftConfigor equivalently:
config = ReftConfig(
layers="all", prefix_positions=3, suffix_positions=0, r=1, orthogonality=False, subtract_projection=False
) # equivalent to DiReftConfig()
In addition, Adapters supports configuring multiple hyperparameters tuned in the ReFT paper in ReftConfig, including:
prefix_positions: number of prefix positionssuffix_positions: number of suffix positionslayers: The layers to intervene on. This can either be"all"or a list of layer idstied_weights: whether to tie parameters between prefixes and suffixes
You can use ReFT adapters exactly as any other adapter type in Adapters:
from adapters import AutoAdapterModel, LoReftConfig
model = AutoAdapterModel.from_pretrained("roberta-base")
config = LoReftConfig()
model.add_adapter("loreft_adapter", config=config)
model.train_adapter("loreft_adapter")
# add training loop ...
Learn more about training adapters in this notebook.
Adapter Merging
![]()
We've expanded support for adapter merging, enabling the efficient combination of trained adapters without additional fine-tuning. Merging multiple adapters into a new one allows for efficient domain, language and task transfer. Adapter Merging is a form of Task Arithmetics (Ilharco et al., 2023; Zhang et al., 2023) and hence also allows increasing or unlearning specific skills. All adapter methods support linear merging. For N adapters with parameters the merged adapter parameters are calculated as:
Where is the weight for each adapter. Example usage:
model.average_adapter(
adapter_name="merged_adapter",
adapter_list=["lora1", "lora2", "lora3"],
weights=[0.2, -0.1, 0.9], # these are the λ_i
combine_strategy="linear",
)
For LoRA adapters, Chronopoulou et al. (2023) have shown that linear combination can work effectively. However, the parameters of the LoRA matrices are interdependent. Hence simple linear combination may not always yield optimal results. Therefore, we support two additional LoRA-specific merging strategies:
combine_strategy = "lora_linear_only_negate_b": As proposed by Zhang et al. (2023) this method only negates the B matrix for negative weights:combine_strategy = "lora_delta_w_svd": Merges the LoRA delta W matrices and then applies SVD to obtain new A and B matrices.
Example usage:
model.average_adapter(
adapter_name="lora_svd_merged",
adapter_list=["lora1", "lora2", "lora3"],
weights=[0.9, -0.7, 0.8],
combine_strategy="lora_delta_w_svd",
svd_rank=8, # "lora_delta_w_svd" requires the "svd_rank" parameter, which determines the r (rank) of the resulting LoRA adapter after singular value decomposition (SVD)
)
Quantized Training
![]()
Quantization of model weights has become an important method for drastically reducing the memory footprint of recent large language models. Quantizing parameters down to 8 bits or 4 bits (Dettmers & Zettlemoyer, 2023) have enabled running large models on limited hardware with minimal performance reduction.
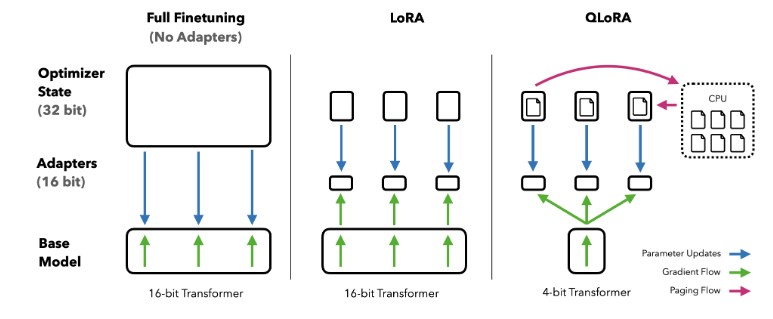
While initially limited to model inference, QLoRA (Dettmers et al., 2023) has proposed combining model quantization with adapter training using LoRA.
QLoRA combines several innovations to reduce the memory footprint while fine-tuning a large LM. In short:
- 4-bit NormalFloat quantization reduces the size of the base model to 4 bits per parameter while optimizing for maximizing the retained information.
- Double quantization additionally quantizes constants required for quantization for additional memory saving.
- Paged optimizers offloads optimizer states into CPU memory when they don't fit into GPU memory and automatically reloads them when needed.
- LoRA training fine-tunes LoRA layers on the task while keeping the quantized base model weights fixes.
Make sure to check out the paper for detailed explanations! The figure below visualizes the key differences between full fine-tuning, LoRA and QLoRA:
Model quantization and paged optimizers are integrated to the Transformers library via the bitsandbytes library:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
# Load 4-bit quantized model
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B",
device_map="auto",
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
),
torch_dtype=torch.bfloat16,
)
Since Adapters v0.2.0, all adapter implementations integrate seamlessly with quantized models, e.g. for QLoRA:
import adapters
from adapters import LoRAConfig
adapters.init(model)
config = LoRAConfig(alpha=16, r=64)
model.add_adapter("qlora", config=config)
model.train_adapter("qlora")
This approach isn't limited to LoRA - you can easily swap out the adapter config here! You can not only train QLoRA, but also QBottleneck adapters, QPrefixTuning and more!
For a full guide, check out our Notebook tutorial for quantized fine-tuning of Llama.
New Models
Whisper
![]()
With the support of Whisper, we introduce the first model in the adapters library to operate in the audio domain, posing a fundamental step towards making our library more diverse for various modalities. Whisper was originally presented by OpenAI in their paper Robust Speech Recognition via Large-Scale Weak Supervision and is a state-of-the-art model for audio processing trained on 680.000 hours of unsupervised data.
Our WhisperAdapterModel builds on the standard encoder-decoder architecture of the Hugging Face Whisper implementation and supports all the methods listed below, as well as flexible adding and removing of heads.
| Model | (Bottleneck) Adapters |
Prefix Tuning |
LoRA | Compacter | Adapter Fusion |
Invertible Adapters |
Parallel block |
Prompt Tuning |
ReFT |
|---|---|---|---|---|---|---|---|---|---|
| Whisper | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
We also support enabling adapter capabilities for existing static head models of the classes WhisperForConditionalGeneration and WhisperForAudioClassification via the init() function.
Since Whisper processes audio, the audio data requires additional processing steps that are different from standard text processing. For more information on that, check out our new notebook tutorial on how to finetune Whisper with LoRA for transcription.
Other Models
Since our initial release, we have also added a bunch of other models:
Go check them out if you are interested!
Hub Updates
Within the last few weeks, we have archived the "original" Hub repository (found at: Adapter-Hub/Hub) released alongside our initial AdapterHub release in 2020. The Hub repository on GitHub is now in read-only mode, meaning no new adapters can be added there.
It's recommended to upload all new adapters to the Hugging Face Model Hub, which will be the only supported Hub for Adapters in the future (Learn more). We have moved all ~300 publicly accessible adapters, including all of our original collection and most third-party contributions over to the Hugging Face Model Hub. Check out our Hugging Face Hub page at: https://huggingface.co/AdapterHub.
In v1.0 of Adapters, attempting to load adapters from the original Hub repo will automatically redirect to loading the same adapter from the Hugging Face Model Hub. There is no breaking change in loading an adapter ID, the same adapter weights will be loaded. However, some parameters related to Hub loading and discovery have been deprecated or removed. Learn more about breaking changes here.
Citation
If you use Adapters in your research, please cite:
@inproceedings{poth-etal-2023-adapters,
title = "Adapters: A Unified Library for Parameter-Efficient and Modular Transfer Learning",
author = {Poth, Clifton and
Sterz, Hannah and
Paul, Indraneil and
Purkayastha, Sukannya and
Engl{\"a}nder, Leon and
Imhof, Timo and
Vuli{\'c}, Ivan and
Ruder, Sebastian and
Gurevych, Iryna and
Pfeiffer, Jonas},
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-demo.13",
pages = "149--160",
}