
Throughout the last few months, the field of parameter-efficient methods for fine-tuning Transformer-based models has seen a wide range of new innovations, proposing new adapter methods (e.g. He et al., 2021; Liu et al., 2022) and applying them to new domains and tasks (e.g. Chen et al., 2022).
With the newest release of our adapter-transformers library, version 3.1, we take a further step towards integrating the diverse possibilities of parameter-efficient fine-tuning methods by supporting multiple new adapter methods and Transformer architectures.
In the following sections, we highlight important new features and methods introduced with the new release. The full changelog can be found here.
You can find adapter-transformers on GitHub or install it via pip:
pip install -U adapter-transformers
New Adapter Methods
With the release of adapter-transformers v3 a few months back, we started the process of integrating new adapter methods.
The new release v3.1 adds three new works that were released throughout the last year, namely LoRA (Hu et al., 2021), UniPELT (Mao et al., 2022) and (IA)^3 (Liu et al., 2022).
Previously, we have already integrated bottleneck adapters (Houlsby et al., 2019), Prefix Tuning (Li and Liang, 2021), parallel adapters, Mix-and-Match adapters (He et al., 2021) and Compacters (Mahabadi et al., 2021). For more on these methods, please refer the blog post for the release of v3. For a more general introduction to working with adapters, please refer to our documentation.
The following table compares the performance of our implementation of LoRA, (IA)^3 and bottleneck adapters, which are described in more detail afterwards, on the GLUE benchmark.
We use roberta-base as the base Transformer model and train for 20 epochs with learning rates of 1e-3, 1e-4 and 1e-4 for (IA)^3, LoRA and bottleneck adapters, respectively.
| Task | Metric | (IA)^3 | LoRA | Adapter (Houlsby) |
|---|---|---|---|---|
| COLA | Matthews Correlation | 59.53 | 58.35 | 59.81 |
| MNLI | Accuracy | 85.98 | 87.15 | 86.68 |
| MRPC | F1 | 89.5 | 90.63 | 90.53 |
| QNLI | Accuracy | 91.75 | 92.82 | 92.7 |
| QQP | F1 | 85.96 | 86.57 | 88.41 |
| RTE | Accuracy | 73.41 | 72.08 | 77.9 |
| SST2 | Accuracy | 93.92 | 94.11 | 94.5 |
| STSB | Spearmanr | 89.78 | 89.82 | 90.58 |
LoRA
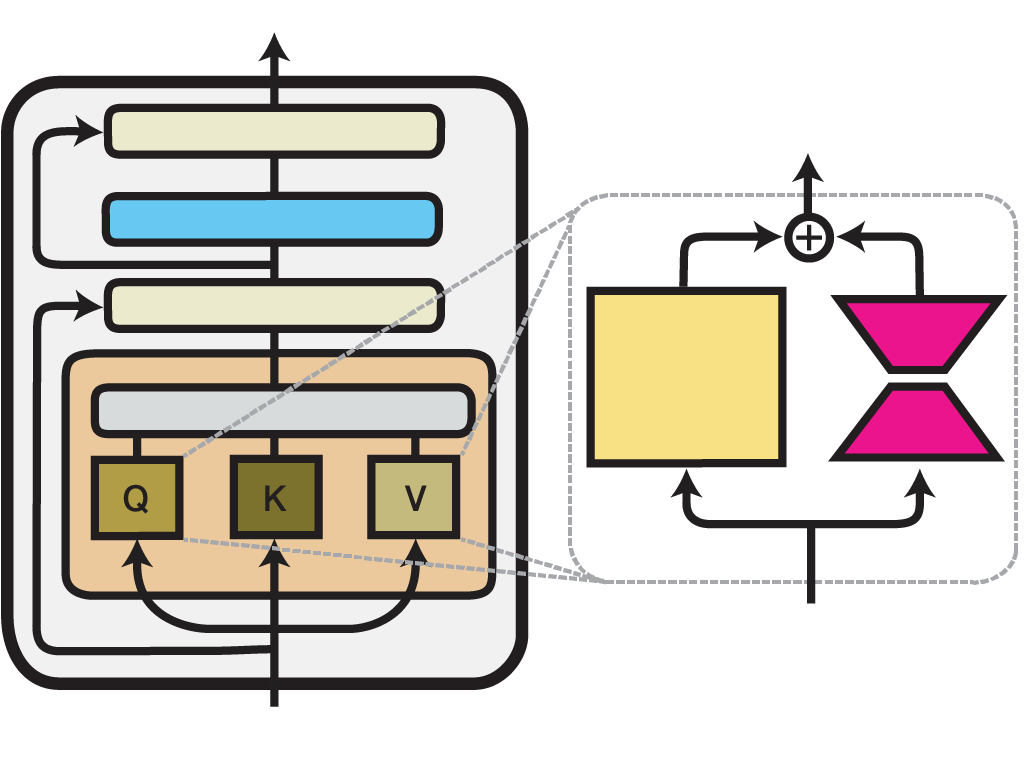
Low-Rank Adaptation (LoRA) is an efficient fine-tuning technique proposed by Hu et al. (2021). LoRA injects trainable low-rank decomposition matrices into the layers of a pre-trained model. For any model layer expressed as a matrix multiplication of the form , it therefore performs a reparameterization, such that:
Here, and are the decomposition matrices and , the low-dimensional rank of the decomposition, is the most important hyperparameter.
While, in principle, this reparameterization can be applied to any weights matrix in a model, the original paper only adapts the attention weights of the Transformer self-attention sub-layer with LoRA.
adapter-transformers additionally allows injecting LoRA into the dense feed-forward layers in the intermediate and output components of a Transformer block.
You can configure the locations where LoRA weights should be injected using the attributes in the LoRAConfig class.
Example:
from transformers.adapters import LoRAConfig
config = LoRAConfig(r=8, alpha=16)
model.add_adapter("lora_adapter", config=config)
In the design of LoRA, Hu et al. (2021) also pay special attention to keeping the inference latency overhead compared to full fine-tuning at a minimum.
To accomplish this, the LoRA reparameterization can be merged with the original pre-trained weights of a model for inference.
Thus, the adapted weights are directly used in every forward pass without passing activations through an additional module.
In adapter-transformers, this can be realized using the built-in merge_adapter() method:
model.merge_adapter("lora_adapter")
To continue training on this LoRA adapter or to deactivate it entirely, the merged weights first have to be reset again:
model.reset_adapter("lora_adapter")
(IA)^3
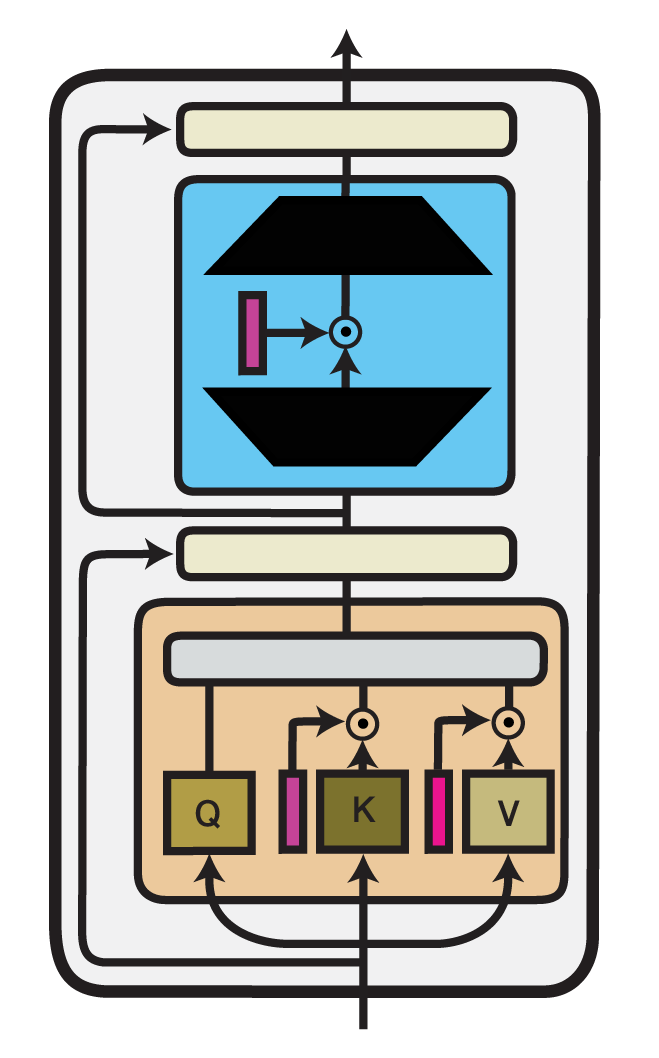
Infused Adapter by Inhibiting and Amplifying Inner Activations ((IA)^3) is an efficient fine-tuning method proposed within the T-Few fine-tuning approach by Liu et al. (2022). (IA)^3 introduces trainable vectors into different components of a Transformer model which perform element-wise rescaling of inner model activations. For any model layer expressed as a matrix multiplication of the form , it therefore performs an element-wise multiplication with , such that:
Here, denotes element-wise multiplication where the entries of are broadcasted to the shape of .
Example:
from transformers.adapters import IA3Config
config = IA3Config()
model.add_adapter("ia3_adapter", config=config)
The implementation of (IA)^3, as well as the IA3Config class, are derived from the implementation of LoRA, with a few main modifications.
First, (IA)^3 uses multiplicative composition of weights instead of additive composition as in LoRA.
Second, the added weights are not further decomposed into low-rank matrices.
Both of these modifications are controlled via the composition_mode configuration attribute by setting composition_mode="scale".
Additionally, as the added weights are already of rank 1, r=1 is set.
Beyond that, both methods share the same configuration attributes that allow you to specify in which Transformer components rescaling vectors will be injected.
Following the original implementation, IA3Config adds rescaling vectors to the self-attention weights (selfattn_lora=True) and the final feed-forward layer (output_lora=True).
Further, you can modify which matrices of the attention mechanism to rescale by leveraging the attn_matrices attribute.
By default, (IA)^3 injects weights into the key ('k') and value ('v') matrices, but not in the query ('q') matrix.
Finally, similar to LoRA, (IA)^3 also allows merging the injected parameters with the original weight matrices of the Transformer model. E.g.:
# Merge (IA)^3 adapter
model.merge_adapter("ia3_adapter")
# Reset merged weights
model.reset_adapter("ia3_adapter")
UniPELT
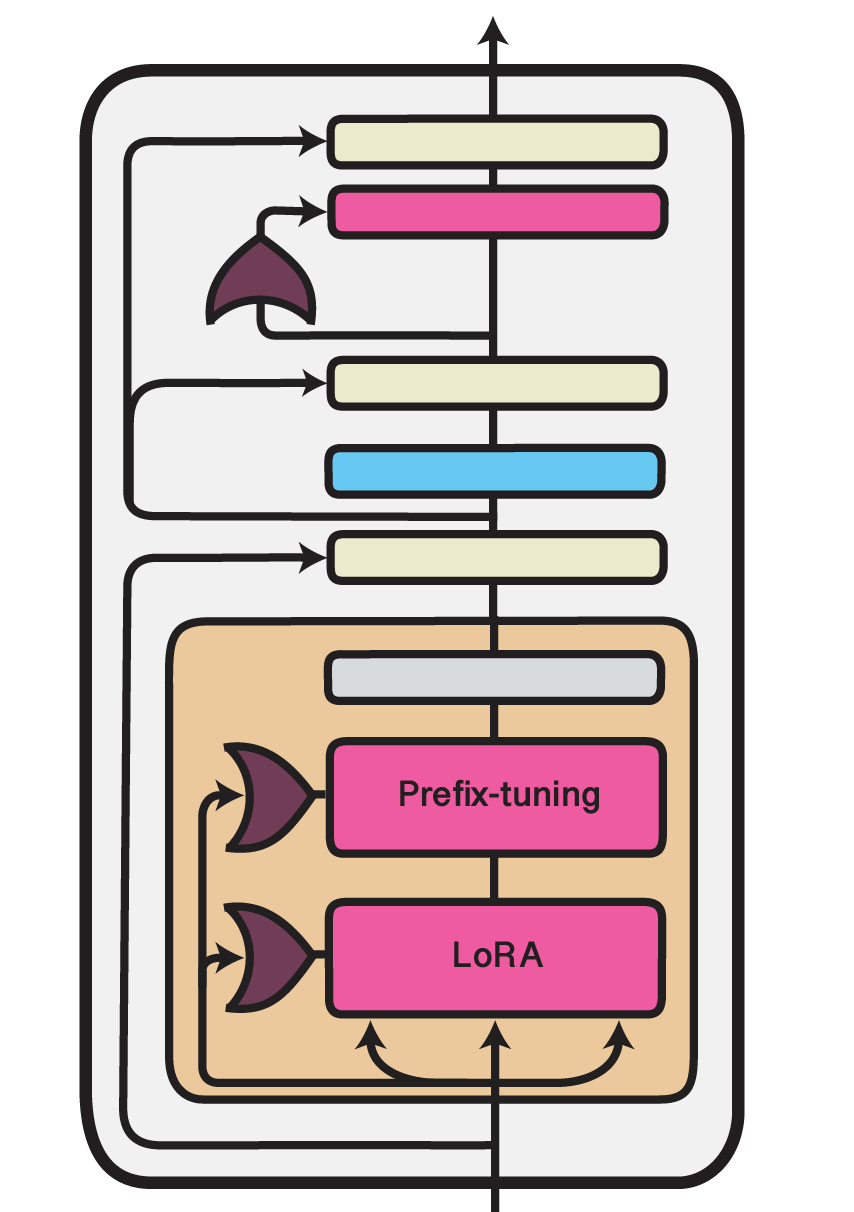
An approach similar to the work of He et al. (2021) is taken by Mao et al. (2022) in their UniPELT framework. They, too, combine multiple efficient fine-tuning methods, namely LoRA, Prefix Tuning and bottleneck adapters, in a single unified setup. UniPELT additionally introduces a gating mechanism that controls the activation of the different submodules.
Concretely, for each adapted module , UniPELT adds a trainable gating value that is computed via a feed-forward network () and sigmoid activation () from the Transformer layer input states ():
These gating values are then used to scale the output activations of the injected adapter modules, e.g. for a LoRA layer:
In the configuration classes of adapter-transformers, these gating mechanisms can be activated via use_gating=True.
The full UniPELT setup can be instantiated using UniPELTConfig1:
from transformers.adapters import UniPELTConfig
config = UniPELTConfig()
model.add_adapter("unipelt", config=config)
which is identical to the following ConfigUnion:
from transformers.adapters import ConfigUnion, LoRAConfig, PrefixTuningConfig, PfeifferConfig
config = ConfigUnion(
LoRAConfig(r=8, use_gating=True),
PrefixTuningConfig(prefix_length=10, use_gating=True),
PfeifferConfig(reduction_factor=16, use_gating=True),
)
model.add_adapter("unipelt", config=config)
Finally, as the gating values for each adapter module might provide interesting insights for analysis, adapter-transformers comes with an integrated mechanism of returning all gating values computed during a model forward pass via the output_adapter_gating_scores parameter:
outputs = model(**inputs, output_adapter_gating_scores=True)
gating_scores = outputs.adapter_gating_scores
Note that this parameter is only available to base model classes and AdapterModel classes.
In the example, gating_scores holds a dictionary of the following form:
{
'<adapter_name>': {
<layer_id>: {
'<module_location>': np.array([...]),
...
},
...
},
...
}
The following table shows some initial results when running our UniPELT implementation. All adapter setups are trained for 20 epochs with a learning rate of 1e-4. Reported scores are accuracies 2.
| Task | Model | UniPELT (ours) | UniPELT (paper) |
|---|---|---|---|
| SST-2 | bert-base-uncased | 92.32 | 91.51 |
| SST-2 | roberta-base | 94.61 | --- |
| MNLI | bert-base-uncased | 84.53 | 83.89 |
| MNLI | roberta-base | 87.41 | --- |
Further Updates
New model integrations
Version 3.1 adds adapter support to the DeBERTa and Vision Transformer (ViT) architectures already integrated into HuggingFace Transformers.
The ViT integration is of particular interest as it opens the application area of our adapter implementations to the computer vision domains. While most of the current work on adapter methods for Transformers happened in the NLP domain, adapters for Transformers in the vision domain have also been investigated recently (He et al., 2022; Chen et al., 2022).
Below, we show some initial results of our ViT integration, using google/vit-base-patch16-224 as the pre-trained base model:
| Task | Full FT | Houlsby | Pfeiffer | LoRA | Prefix Tuning |
|---|---|---|---|---|---|
| CIFAR-10 | 98.88 | 98.72 | 99.09 | 98.84 | 98.76 |
| CIFAR-100 | 92.08 | 92.4 | 92.08 | 91.77 | 91.76 |
All scores are accuracies on the evaluation set 2.
adapter_summary() method
The new release adds an adapter_summary() method that provides information on all adapters currently loaded into a base model in tabular form.
The method can be used as follows:
model = AutoAdapterModel.from_pretrained("roberta-base")
for name, config in ADAPTER_CONFIG_MAP.items():
model.add_adapter(name, config=config)
print(model.adapter_summary())
... which produces this output:
================================================================================
Name Architecture #Param %Param Active Train
--------------------------------------------------------------------------------
pfeiffer bottleneck 894,528 0.718 0 1
houlsby bottleneck 1,789,056 1.435 0 1
pfeiffer+inv bottleneck 1,190,592 0.955 0 1
houlsby+inv bottleneck 2,085,120 1.673 0 1
compacter++ bottleneck 28,576 0.023 0 1
compacter bottleneck 57,088 0.046 0 1
prefix_tuning prefix_tuning 9,872,384 7.920 0 1
prefix_tuning_flat prefix_tuning 552,960 0.444 0 1
parallel bottleneck 7,091,712 5.689 0 1
scaled_parallel bottleneck 7,091,724 5.690 0 1
lora lora 294,912 0.237 0 1
ia3 lora 55,296 0.044 0 1
mam union 22,493,984 18.046 0 1
unipelt union 11,083,376 8.892 0 1
--------------------------------------------------------------------------------
Full model 124,645,632 100.000 1
================================================================================
Transformers upgrade
Version 3.1 of adapter-transformers upgrades the underlying HuggingFace Transformers library from v4.17.0 to v4.21.3, bringing many new features and bug fixes created by HuggingFace.
References
- Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., & Chen, W. (2022). LoRA: Low-Rank Adaptation of Large Language Models. ArXiv, abs/2106.09685.
- Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M., & Raffel, C. (2022). Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning. ArXiv, abs/2205.05638.
- Mao, Y., Mathias, L., Hou, R., Almahairi, A., Ma, H., Han, J., Yih, W., & Khabsa, M. (2021). UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning. ArXiv, abs/2110.07577.
- He, X., Li, C., Zhang, P., Yang, J., & Wang, X. (2022). Parameter-efficient Fine-tuning for Vision Transformers. ArXiv, abs/2203.16329.
- Chen, S., Ge, C., Tong, Z., Wang, J., Song, Y., Wang, J., & Luo, P. (2022). AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition. ArXiv, abs/2205.13535.
-
Note that the implementation of UniPELT in
adapter-transformersfollows the implementation in the original code, which is slighlty different from the description in the paper. See here for more. ↩ -
Reported results for
adapter-transformersonly contain a single run each without hyperparameter tuning. ↩↩